Open Know-Where (OKW): Where are we now?
Closing out 2022 and kicking off the new year, OKW WG community members met to discuss shared experiences with using OKW as experienced by OKW Data Awardees, DevOps, and community members involved in OKW’s application to mapping. These conversations, captured in the OKW WG rolling meeting agenda, focused on multiple aspects of OKW standard, and OKW as an initiative; what differentiates between the two and implications for governance, policy, and operational workplans are the focal point of a technical strategy developed by @max_w.
For this plan, outlined below, we welcome community feedback - your questions, comments, concerns and/or expressions of interest for involvement are welcomed and can be added to this thread. Updates regarding the OKW Manufacturing World Map Data Awards will be attached to the related call for applications thread.
OKW Discussion Points for Continual Review and Community Input
One of the key initiatives that the IOPA set out to implement is to create ways to Improve the discovery of manufacturing facilities, equipment and capabilities within the manufacturing industry and maker communities.
OKW v1 Specification
Towards that end, the IOPA released the Open Know-Where (OKW) standard for documenting and sharing information about the location of manufacturing facilities and capabilities globally. The specification, released on 28 April 2021, was originally designed to be adopted by anyone who collects or shares data about manufacturing capabilities, including government, non-government organisations (NGOs), aid agencies, mapping communities, makers and platforms.
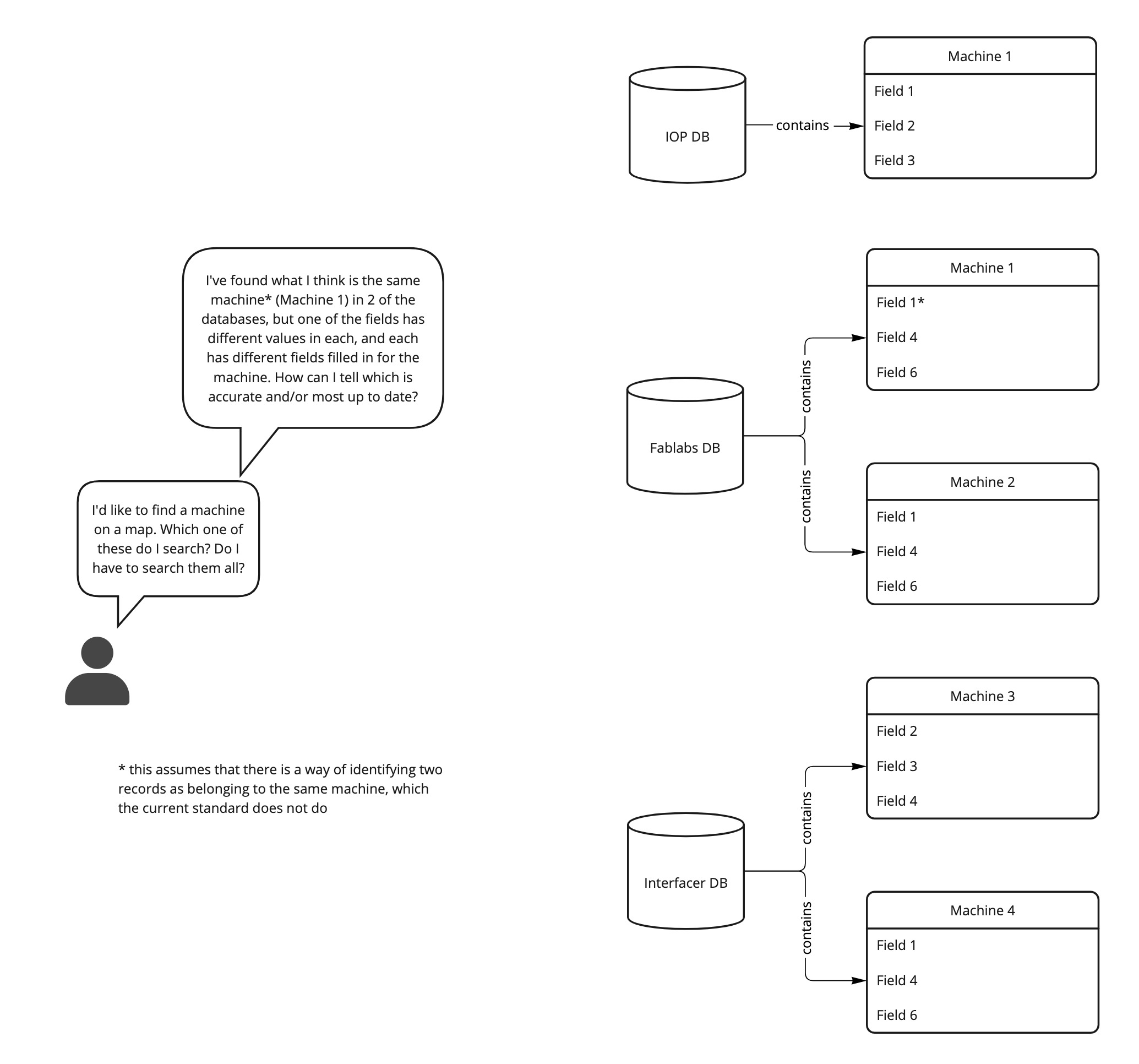
Figure 1: User journey for using OKW v1
The original specification was built on the implied premise that if disparate organisations and initiatives collected data about the location and other metadata about machines and labeled the data the same way across datasets, this would lead to the emergence of a system or mechanism by which machinery and manufacturing capabilities all over the world could be located based on specific manufacturing requirements or machine specifications. The specification does not include provision for how data can be deduplicted, or validated between various datasets that are labeled according to the specification.
The IOPA as Data Aggregator
The IOPA has also been working towards building an online map of manufacturing facilities which aggregates data collected by IOPA members and contributors, as well as manufacturing facility and machine location data held in various platforms and historical datasets. It has not been possible to continue building such a data aggregation mapping platform while adhering to the OKW specification. In part this is because the specification does not have provision for the use of unique identifiers for people, facilities, or machines (each of which will require a separate standard / process for creating and managing the identifiers outside the scope of the metadata specification itself).
Continuing this work requires acknowledging that the IOPA is developing a mapping platform / product which needs a development process that is not tied to adhering in its architecture and data schemas to the published OKW Specification. As the following diagram illustrates, this requires building an Extract, Transform, Load (ETL) pipeline with many components, scripts and applications. The diagram also illustrates how the OKW v1 Specification is factored in as one of the ways in which the data can be exported (shown as the “Export as OKW Specification” element), but not as the way the data is stored.
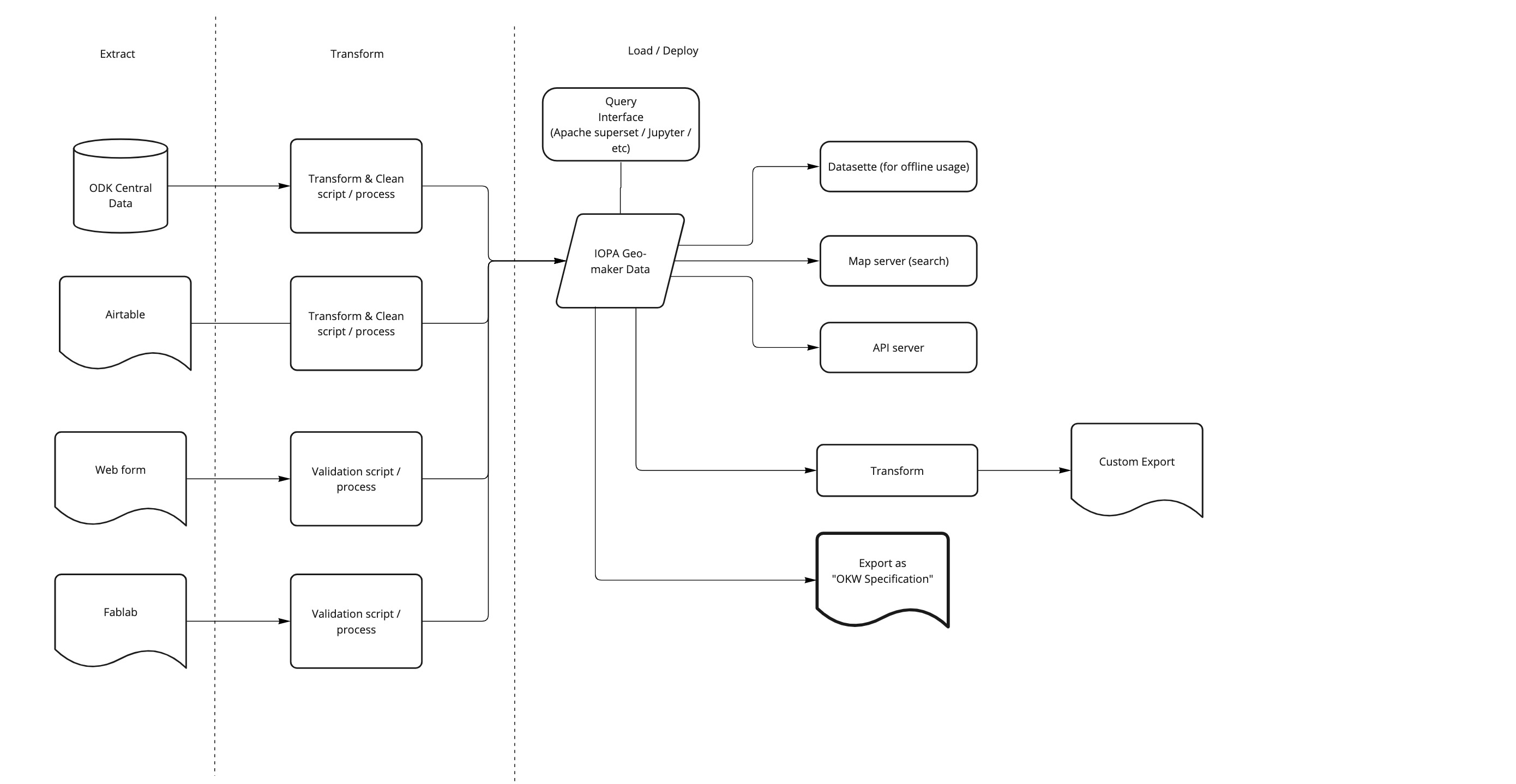
Figure 2: ETL Pipeline, exports, and platforms
Different Models
The purpose in this document isn’t to define the detailed intricacies of moving forward with either the “disparate data sets” model of the OKW v1 Specification, or the “data aggregation” model. Rather it is to highlight that they are two separate models that could have some overlap, but each have different implications in terms of development, community engagement, and organizational processes and needs.
These directions are not mutually exclusive nor exhaustive, and work could be done on both in parallel (e.g the IOPA as “data aggregator” could also be one of the “disparate datasets” as Figure 1 illustrates), if all the required personnel were available. However priorities will need to be decided based on the personnel available.
By way of illustration, these are some of the key ways in which each approach will impact the work of the IOPA secretariat, community engagement, and partnerships.
Being a “data aggregator”
- This would mean that the IOPA’s role would be to identify different sources of data and aggregate them into a single data set/data warehouse that:
- Is publicly queryable via a UI (for humans) and a public API (for computers): will need to develop, amongst many other features, access and permissions specs
- Can be publicly addable/editable: will need to develop edit/review/moderation processes and have adequate resources to carry out data validation and cleaning.
- has mechanisms for merging data from multiple external sources, e.g. protocols and/or processes for handling merge conflicts (e.g if two data sources have conflicting data about the same machine/facility/person
- Partnerships would mean:
- Giving 3rd parties access to the IOPA data (e.g. via APIs)
- Giving the IOPA access to the 3rd party’s data and develop a mechanism for propagating updates to the IOPA
- In this scenario, it doesn’t matter how the data is labeled/structured in each system (whether the IOPA’s “data warehouse”, or 3rd party systems) just that the data can be mapped/transformed adequately when importing/ingesting into the IOPA system, or when exporting (e.g via an API query)
- Data can be exported according to an official specification, but this will not necessarily be the way the data is stored internally (the internal schema)
Maintaining “Disparate Data Sets”
One way to make this approach work would be to develop a way to “synchronise” data between different data managers*. This would mean**:
-
Defining the synchronisation / update protocol between data managers that are part of the project which would
- Have the ability to designate which, amongst the contributing data sets, is the “source of truth” about any particular facility or machine (i.e. resolve conflicts when two data sets have conflicting data about the same machine/facility/person)
- Enable merging of changes to the same facility’s manufacturing capabilities, or the same machine’s properties across multiple data sets
-
The standardisation work (i.e. the role of the IOPA) would be about bringing together data managers* to work out how the data is exchanged, merged, and validated between the different platforms/datasets, rather than how the data is stored and labeled within each platform/dataset (it won’t matter how the data is labeled/structured in each system, just that the data is exchanged in a standardised way).
-
Partnership would mean getting data managers* to collaborate on developing and implementing an as-yet undefined protocol for achieving this kind of “synchronisation”
-
This option will not, in and of itself, create a standard way for end-users to search for machines/facilities. Each platform would still need to implement its own search functionality. Users would choose which platform to use based on which one implements the kind of functionality that best suits their use-cases.
-
a data manager is an organisation that manages a data set of manufacturing facilities and machines
** this list is very high-level and over-simplified. This kind of data synchronisation is extremely challenging even for organisations that try to maintain synchronised copies of their own datasets that are hosted on their own distributed server infrastructure. Trying to achieve it across multiple platforms managed by multiple organisations, each with their own data storage infrastructure is, to put it mildly, a non-trivial undertaking.
Other Models
Neither of these models address (in and of themselves) the need for developing community consensus around the issuing / adoption of unique identifiers for facilities, machines, or people. These unique identifiers are needed in either case, but might be better suited to be implemented via separate standards / processes. The following figure illustrates (at a very simplified high-level) how these identifiers might be used in the case of ensuring data integrity from crowd-sourced submissions:
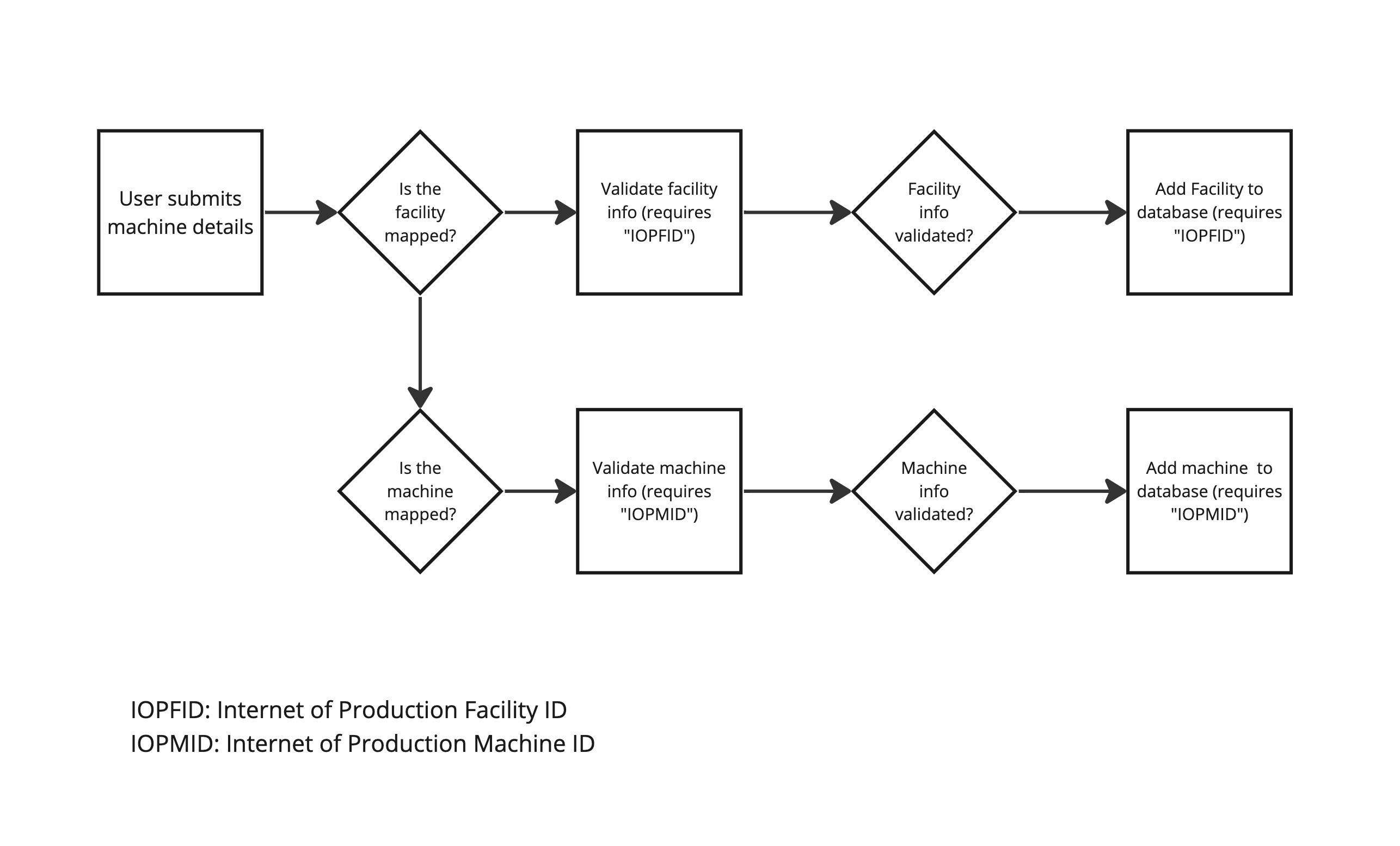
Figure 3: Example of the use of Facility and Machine IDs in a data cleaning, deduplication, and validation process
There is also a case to be made for working on a separate standardized machine taxonomy and / or ontology which would allow for interoperability between the various IOPA initiatives including OKW, OKH and P&S.
OKW vs OKW?
It’s important to not conflate OKW the initiative with OKW the published specification. Part of the challenge with teasing apart these different models and their needs is that OKW the Initiative (that of working on ways to enable the “locatability” of manufacturing facilities, capabilities, and machines in service of a distributed manufacturing paradigm) with OKW the Specification (which is one component of OKW the Initiative). Each of these are separate efforts towards bringing OKW the Initiative to life.
This has implications which we hope to explore in terms of the make-up and role of the OKW Working Group(s):
- Is there agreement that there is a need to “deconflate” OKW as an initiative from the OKW Specification?
- If so, then how do we disambiguate the structure of the Working Group(s) looking at the overall OKW Initiative and those for each of its strands (standards/tools/platforms/protocols)?
- If not, then how do we continue to work on the data aggregation / map server or any of the other efforts, platforms, tools, or protocols that might be proposed related to mapping manufacturing capabilities, facilities, and machines?
Things to aspire to generally (needed for OKW and other initiatives):
- Human-centred design
- Define personas
- Define use-cases — from a human-centred design perspective (ie based upon an explicit understanding of users, tasks, and environments).
- Define constraints