Open-Know-Where data-schema. Considerations and design choices.
Mission:
Design a data source, that enables people to engage in distributed manufacturing. Following FAIR principles, and contributing to the Open-Source Ecosystem.
Open-Know-Where has the mission of enabling Distributed; Manufacturing, Economies, and Disaster/Humanitarian responses.
Considerations:
The Open-Know-Where is on a transition from writing Geo-location data reports to offering Open Databases, and ETL Aggregation and manufacturing data Validation specifications.
We have explored the internet analyzing data from stakeholders and published solutions. Our resources have focus on researching and developing Proof of Concept Resources, Metadata Specifications and Data MVPs.
Defining the Open-Know-Where:
-
The purpose of Open-Know-Where is offering a valuable knowledge source based on data collected from the global Distributed Manufacturing Ecosystem.
-
This is a group of organizations working towards developing projects data and specifications around distributed manufacturing.
-
Explored use cases:
-
Value Proposition:
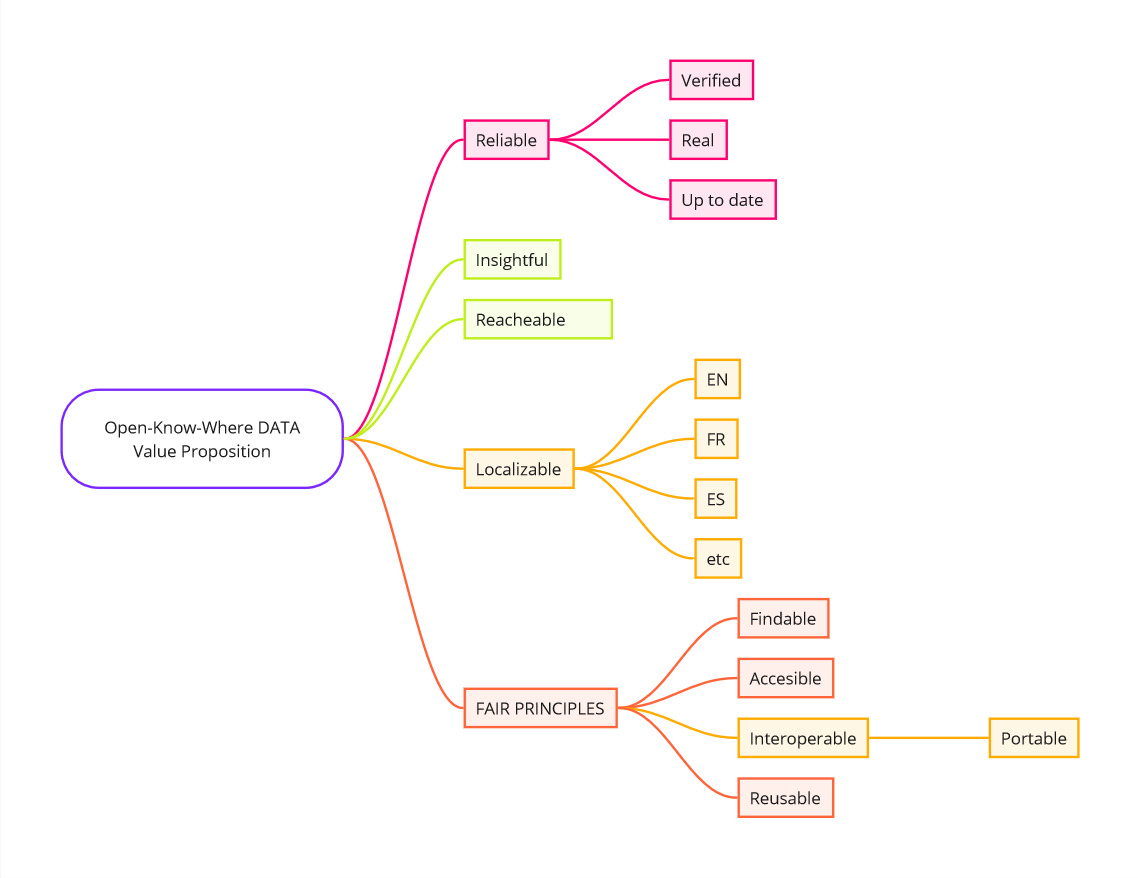
Proof of concept, and findings:
Data from organizations like FabLabs.io, Makery, Vulca/MakerTour, Make.works, Makezine, and Hackerspaces.org have different data schemas and purposes. While some of them try to classify and locate manufacturing locations, others provide a map, and URL for further details.
Data validation processes are inconsistent, some platforms need one or two referrals and other accept any kind of input for their data, without inspection or validation time. This poses a challenge for providing reliable data.
While scrapping data from around 15 different sources estimating the inputs above 40k entries total, there are insights coming from the identification of common fields and the classification of data:
- Data is inconsistent and dependable on the interest of the collectors.
- Data comes as map/geo-location data, tables, APIs and complex data entries, as all are valuable sources of information, normalizing data and designing an inclusive schema is needed.
For more information review the data scrapping notebooks
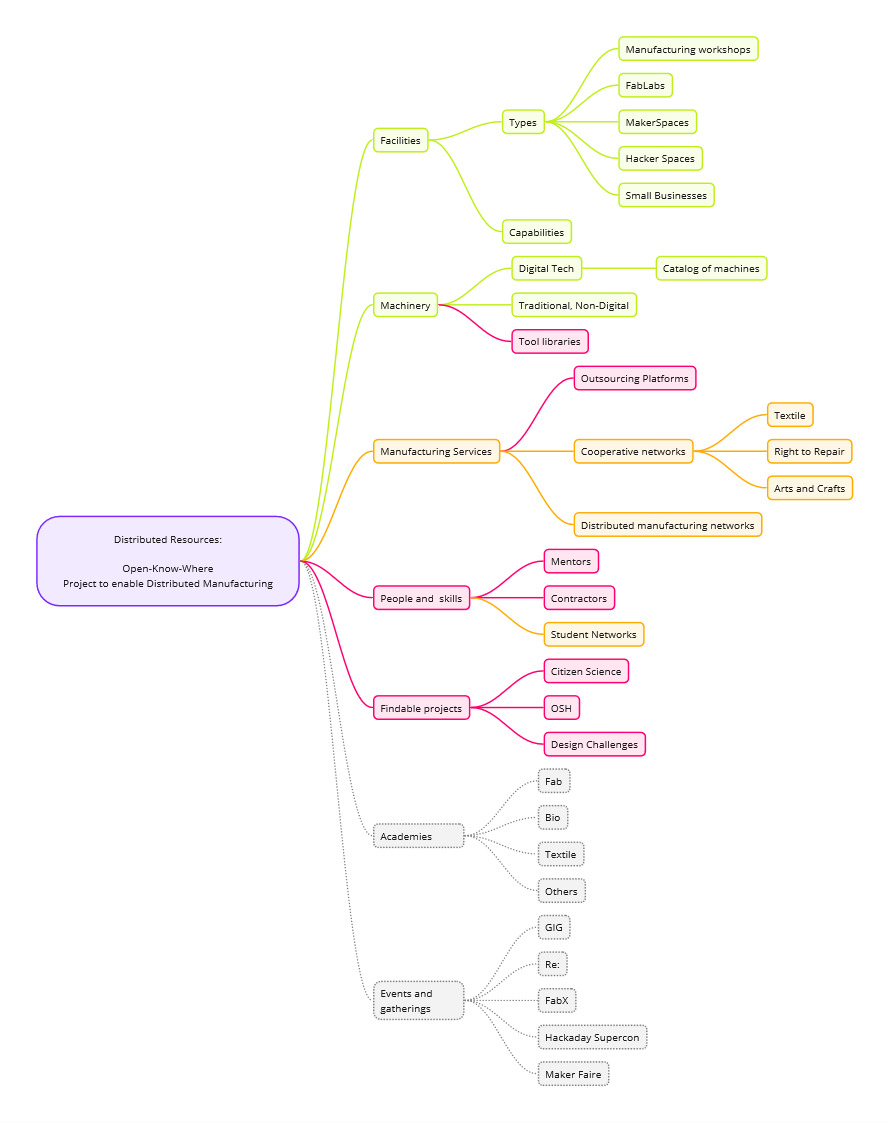
Defining a Distributed Resource:
- The Open-Know-Where Distributed Resources Data; is composed by Facilities, Machinery, Machining services, People&Skills, and Findable Projects. This is the result of observations and (Re)search on “How to use data and enable distributed manufacturing?”
Pipelines for data aggregation:
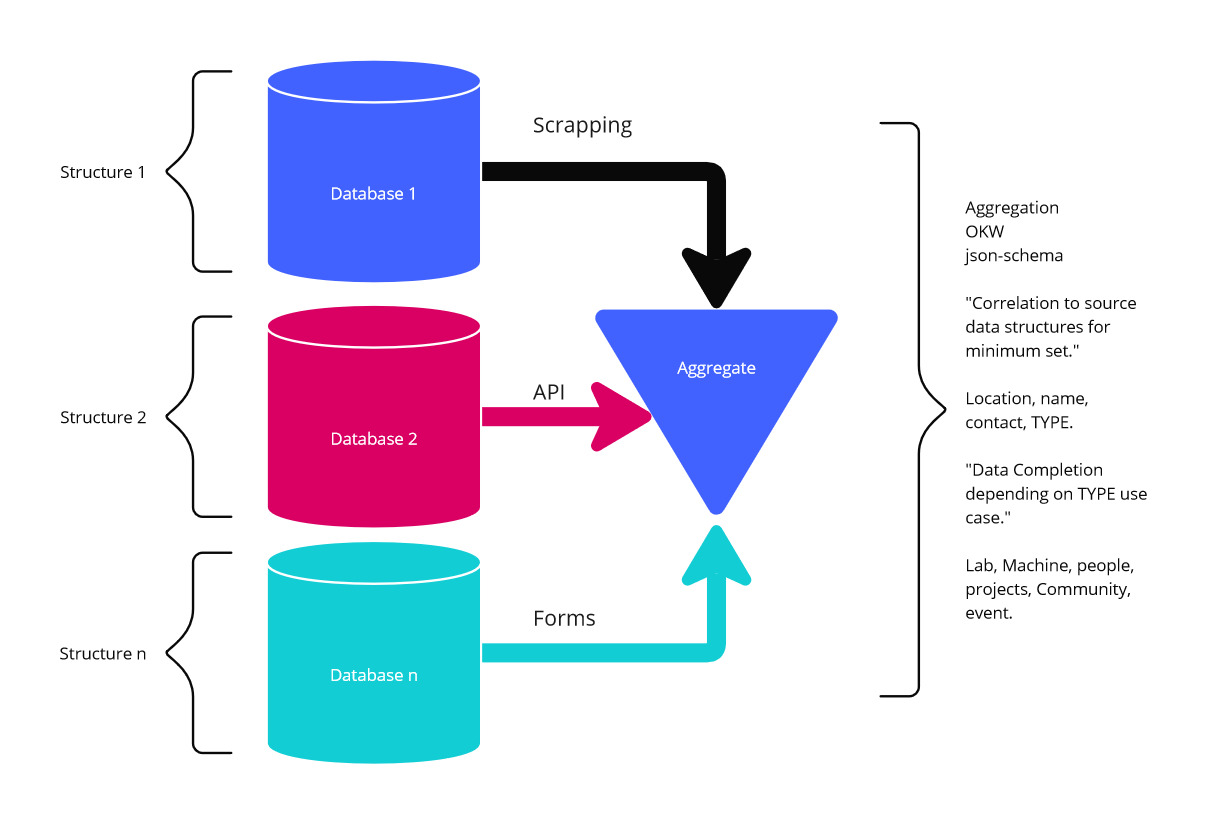
The data comes from the Proof-of-Concept scrapping notebooks, the next step is changing the Python code to a Pipeline that can be orchestrated and integrated into a Docker container, which will deploy a database(PostgreSQL), an OpenAPI generated Python-Flask API server and provide a local Open-Know-Where data platform.
OKW Data Schema:
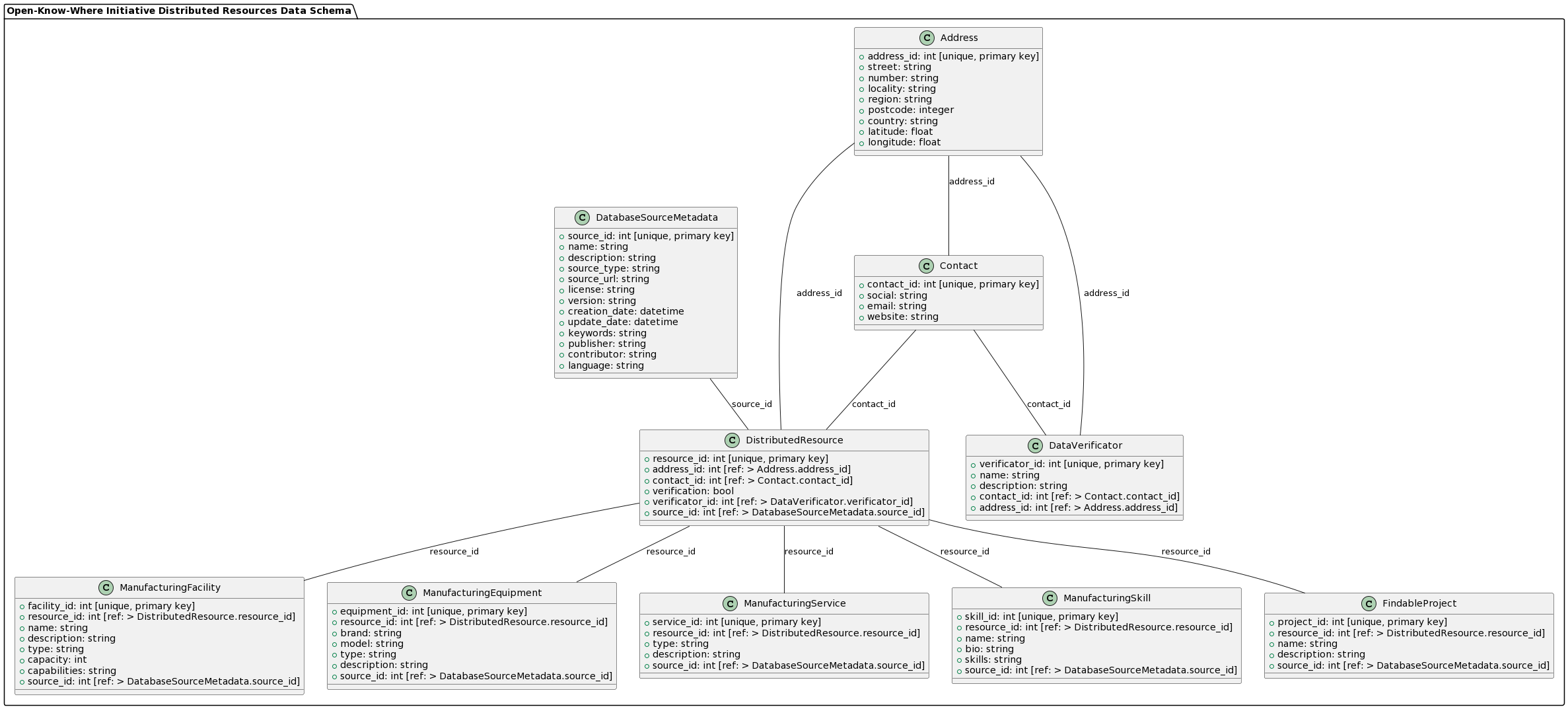
-
This is a proposal for the data-schema, the JSON file is here.
-
A Master Version of the Schema in RDF Turtle format would likely be written as it allows to more detailed and referenced data definitions.
Design choices for the OKW data-schema:
Privacy and security:
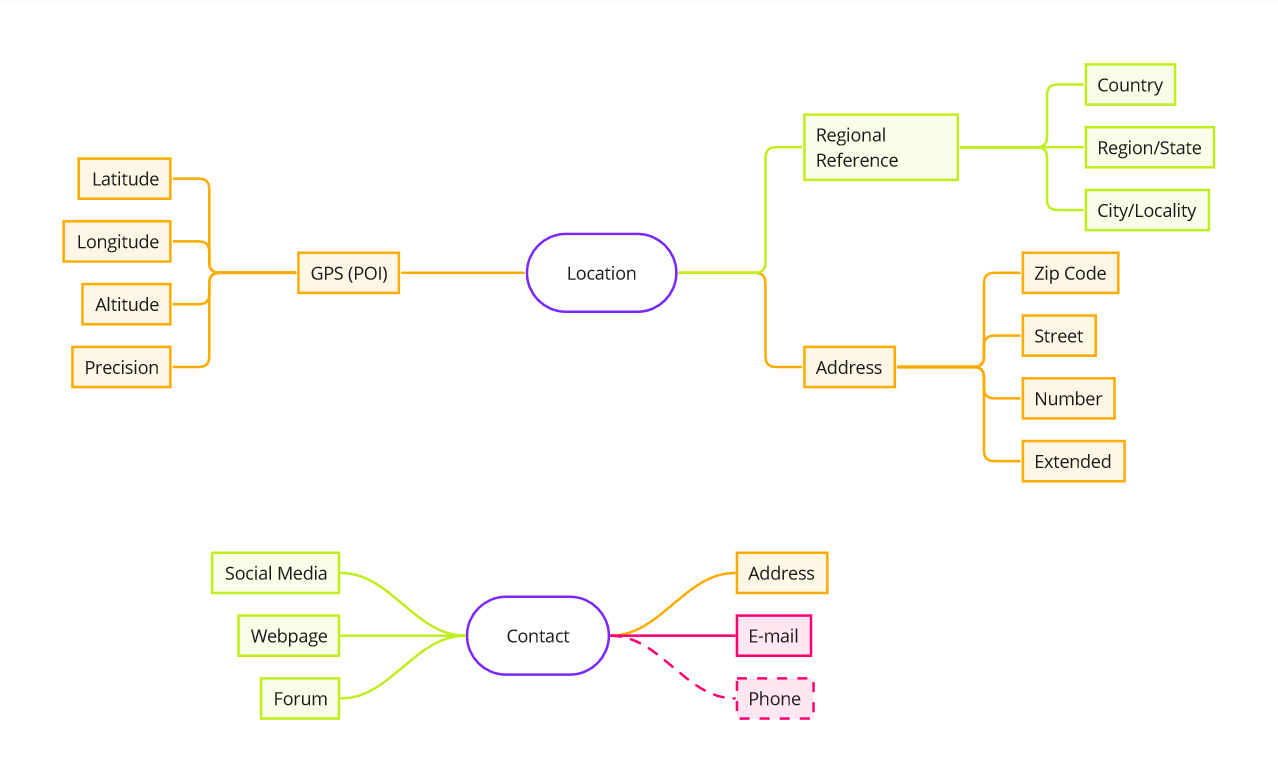
Following GPDR and other related data privacy regulations there’s the following data design considerations:
- The minimum location data required is Country and Zip Code.
- The minimum contact data required is social media handler, URL or Forum user.
*Data completion would be required in most cases for normalization. - GPS at Point of Interest is an optional requirement.
- Geo coding and its reversed process could be used to verify and validate the data records.
- For contact information telephonic numbers are discouraged as they pose a threat to privacy and enable for scamming, etc. a mailing or social media reach would likely be more convenient for contact information verification.
- Anonymized data would be shared on regards of people and skills. Skills seem to be more adequate to share instead of any social media or person name. (For discussion on Working Group.)
On Data validation:
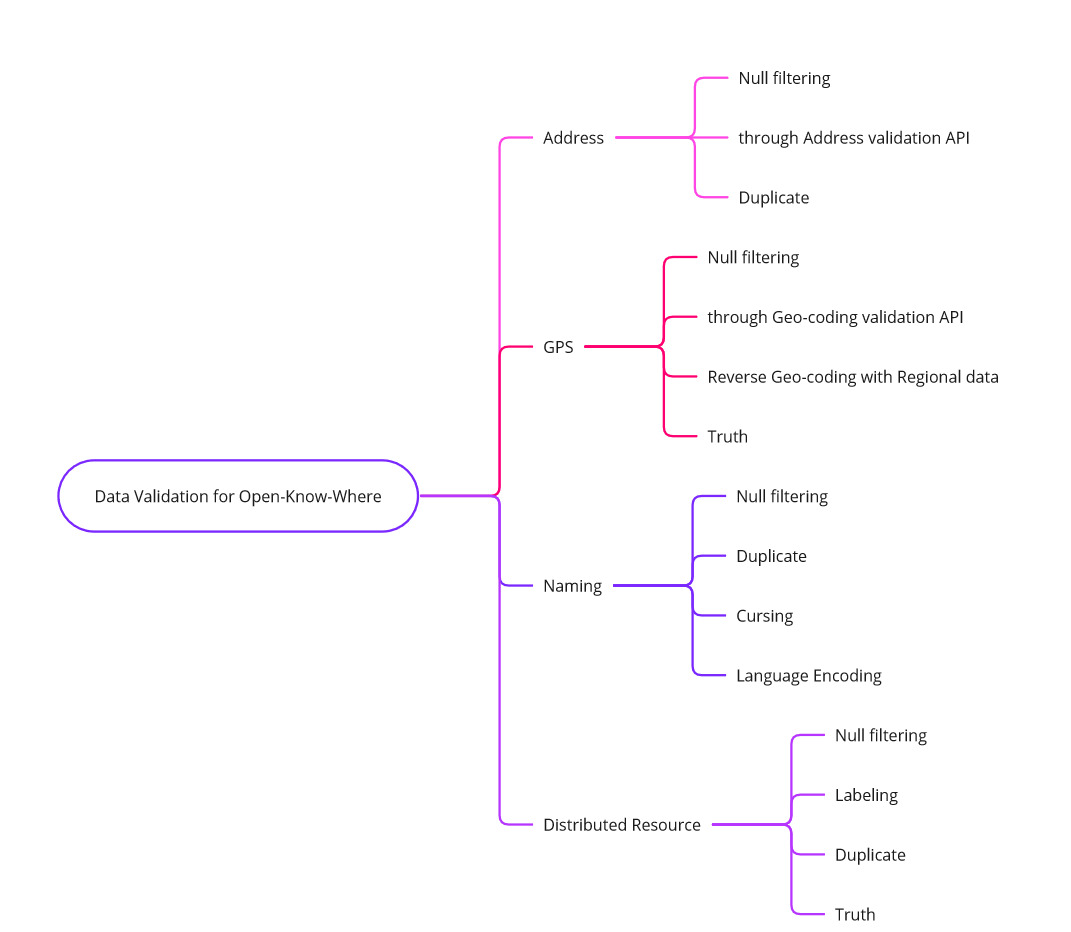
A process needs to be defined and documented for the republishing of the Open-Know-Where metadata specification. An initial set of critical validation data elements are described on the image shown.
Minimum set of data required:
For the data to be served following the purposes and mission of the Open-Know-Where this is a schema for the minimum set of data needed by the data collector or platform.
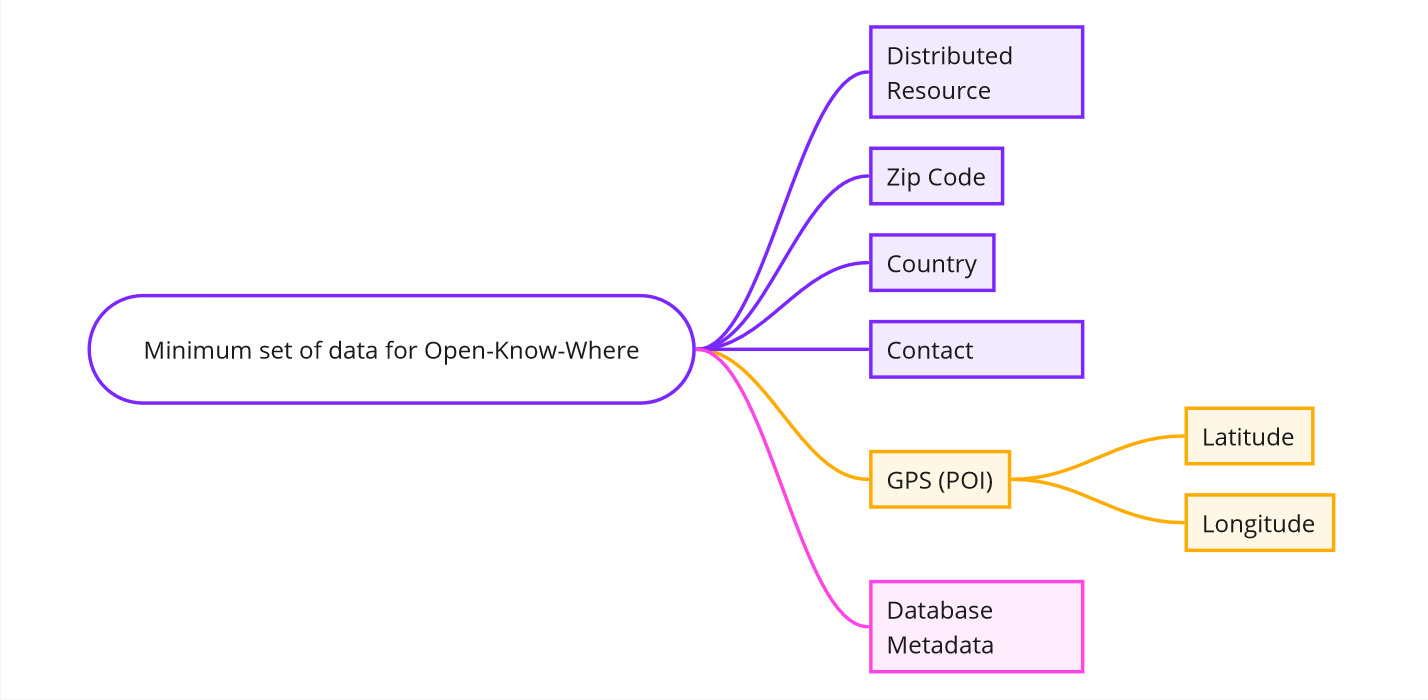
The data also considers database metadata following the OpenData Discovery Specification.
API design, and implementation:
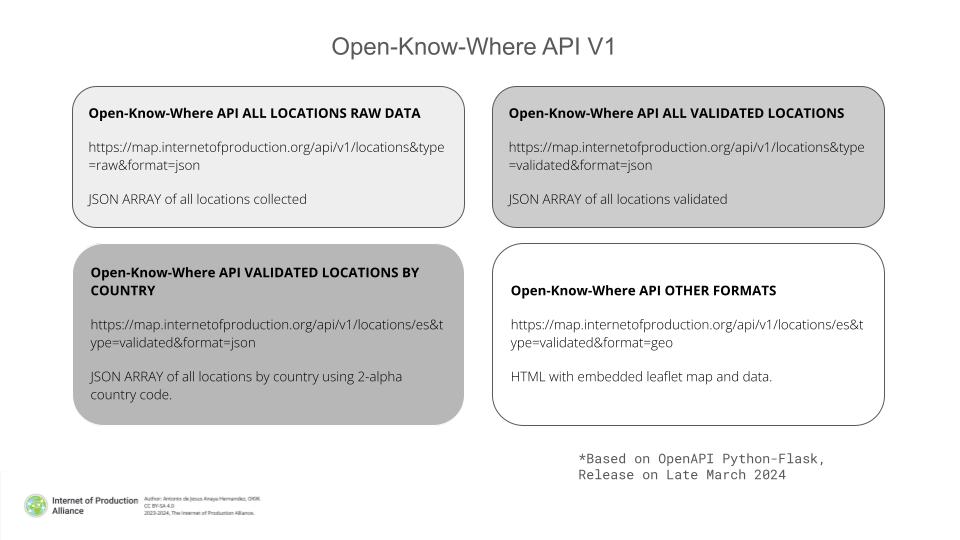
A API specification is being defined using OpenAPI formerly Swagger tools for:
- Design and definition.
- Python-Flask API Server.
The Pipelines and orchestration would be defined and integrated into a DockerFile.
Conclusion:
This introduction to the Open-Know-Where data-schema and its design choices, is written for the community, for informative purposes and entry point of contributions.
As the Action plan describes an MVP and proposals would be delivered for the community to evaluate.
This work is a proposal. Reach out for questions or suggestions, as the challenge of providing a consistent data source has many difficulties that are unlikely to be solved without community feedback.
Future:
This is the foundation for a data system, with the mission of enabling distributing manufacturing, but in the horizon distributed economies and other activities would be benefited by this approach and derivatives.